





SiFive Blog
The latest insights, and deeper technology dives, from RISC-V leaders

Part 3: High-Bandwidth Accelerator Access to Memory: Enabling Optimized Data Transfers with RISC-V
This is the third in a series of blogs about Domain-specific accelerators (DSAs), which are becoming increasingly common in system-on-chip (SoC) designs. Part #1 addressed the challenges associated with data transfers between DSAs and the core complex, and showed how RISC-V offers a unique opportunity to optimize fine-grain communication between them and improve core-DSA interaction performance. Part #2 addressed the challenges associated with point-to-point ordering between cores and DSA memory, and how RISC-V offers a unique opportunity to optimize high-bandwidth communication between cores and DSAs. This third installment will focus on the challenges associated with data transfers between DSA and memories, such as DDR, LPDDR or HBM, and explain how SoCs based on RISC-V can use an alternate approach to write the data directly to memory.
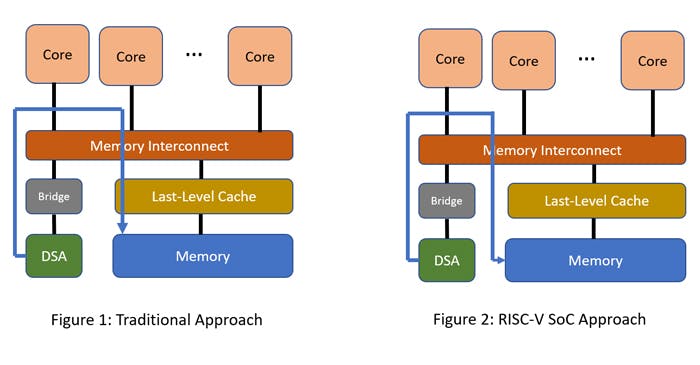
To recap, a DSA provides higher performance per watt by optimizing the specialized function it implements. Examples of DSAs include compression/decompression units, random number generators and network packet processors. A DSA is typically connected to the core complex using a standard IO interconnect, such as an AXI bus (Figure 1).
SoCs based on RISC-V offer a unique opportunity to optimize high-bandwidth data transfers between a DSA and memory. DSAs often need to transfer their data to memory, such as DDR, LPDDR or HBM memories. Often this is accomplished using a DMA (Direct Memory Access) engine.
The difficulty in the traditional approach (Figure 1) is that such data transfers often involve allocating the data in the Last-Level Cache first. This can significantly slow down accesses, particularly if the volume of transferred data is greater than the size of the Last-Level Cache.
Figure 2 shows that SoCs based on RISC-V can use an alternate approach where they can write the data directly to memory, bypassing the Last-Level Cache. This can be achieved by marking the data being written as uncached. Alternatively, the DMA engine can provide a hint to the Last-Level Cache to not allocate the data in the Last-Level Cache, but to write directly to memory. In this scenario, the data is still marked as cacheable, so any other cached copy of the data must be invalidated within the processor complex.
See more details about SiFive’s standard cores, or to customize and build domain-specific RISC-V cores, please visit sifive.com/risc-v-core-ip
Read the other posts in this series:
- Part 1: High-Bandwidth Accelerator Access to Memory: Enabling Optimized Data Transfers with RISC-V
- Part 2: High-Bandwidth Core Access to Accelerators: Enabling Optimized Data Transfers with RISC-V
- Part 3: High-Bandwidth Accelerator Access to Memory: Enabling Optimized Data Transfers with RISC-V
Shubu Mukherjee


Read more Insights from the RISC-V Experts

Inside the SiFive Performance™ P570 Gen 3: High Performance Efficiency for Next-Generation Consumer and Commercial Applications

P570 Gen 3: A System Perspective
