





SiFive Blog
The latest insights, and deeper technology dives, from RISC-V leaders

SiFive Intelligence X280 as AI Compute Host: Google Datacenter Case Study
At the AI Hardware Summit in Santa Clara, September 14th, Krste Asanovic, SiFive Co-Founder and Chief Architect, took to the stage with Cliff Young, Google TPU Architect and MLPerf Co-Founder, to reveal how the latest SiFive Intelligence™ X280 processor with the new SiFive Vector Coprocessor Interface Extension (VCIX) is being used as the AI Compute Host to provide flexible programming combined with the Google MXU (systolic matrix multiplier) accelerator in the datacenter. They also talked about why this type of architecture is becoming popular for AI/ML workloads, and how, with this configuration, SiFive provides essential compute capabilities so Google can focus on deep learning SOC development. A video of the talk is expected to be available in early October.

SIFive Intelligence X280
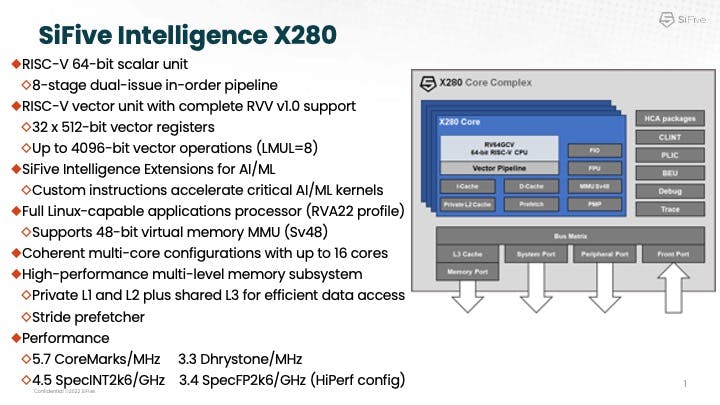 The SiFive Intelligence X280 is a multi-core capable RISC-V processor with vector extension, optimized for AI/ML applications in the datacenter.
As Krste explained, the X280 has a 64-bit applications processor plus an expanded vector unit supporting the RISC-V Vector 1.0 ratified standard, providing a full featured processor designed for vector compute executing standard software. The X280 has 32, 512-bit registers and allows you to gang multiple vector registers together to make a longer vector (up to 8 in a row). This allows operations at up to 4096-bits, which helps reduce power and increase optimizations on cohorts where you have longer vectors.
The SiFive Intelligence X280 is a multi-core capable RISC-V processor with vector extension, optimized for AI/ML applications in the datacenter.
As Krste explained, the X280 has a 64-bit applications processor plus an expanded vector unit supporting the RISC-V Vector 1.0 ratified standard, providing a full featured processor designed for vector compute executing standard software. The X280 has 32, 512-bit registers and allows you to gang multiple vector registers together to make a longer vector (up to 8 in a row). This allows operations at up to 4096-bits, which helps reduce power and increase optimizations on cohorts where you have longer vectors.
SiFive also offers the SiFive Intelligence extensions, which add custom instructions to optimize AI/ML workloads. The X280 runs a full RISC-V software stack as well as a hypervisor. It is a highly efficient, Linux-capable processor with full applications processor support, supporting up to 48-bit virtual memory space, and private L1 and L2 caches. The vector streams from the L2 cache and all cores share the L3 cache. With the latest X280, SiFive offers improved software compilers for higher performance, a very capable applications core, with a very wide vector unit, and support for large cache coherent multi-processor configurations.
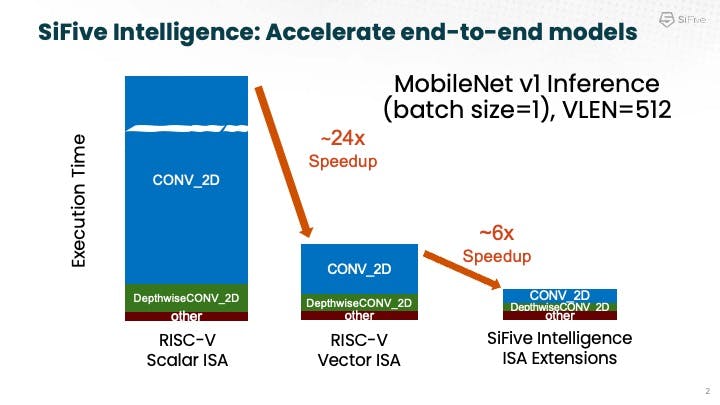 The chart above shows an example of AI acceleration with Mobilenet, delivering a huge 24x speed up with the X280 standard Vector instructions (vs. the scalar ISA), and then another ~6x acceleration with the SiFive Intelligence extensions. Krste also pointed out that the X280 can run by itself, performing inference tasks at the edge, where it can also act as an apps processor and inference engine for smaller workloads.
The chart above shows an example of AI acceleration with Mobilenet, delivering a huge 24x speed up with the X280 standard Vector instructions (vs. the scalar ISA), and then another ~6x acceleration with the SiFive Intelligence extensions. Krste also pointed out that the X280 can run by itself, performing inference tasks at the edge, where it can also act as an apps processor and inference engine for smaller workloads.
Game-changing VCIX
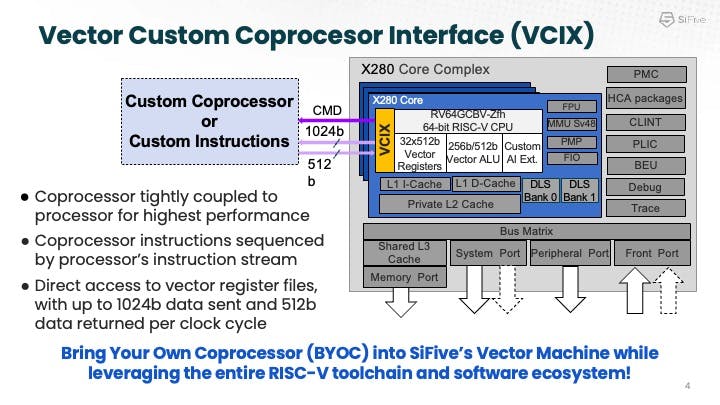
After the introduction of the X280, SiFive started seeing a lot of customers using it as a companion core. As shown above, the X280 has many features to accelerate AI and ML, but it’s not a massive AI accelerator that is traditionally built for datacenters. Customers building these massive accelerators found they had a bunch of complex compute that needed to be done that their accelerator “really didn’t know how to do.” For example, many found that you need a full featured software stack to run the code that’s not in the kernel that sits on the accelerator. To solve this challenge, customers realized they could put the X280 core next to their large accelerator where it could provide maintenance code and operations code, run kernels that the big accelerator couldn’t do, or provide other valuable extra functions. And the X280 core allowed them to run very fast.
With this real-world customer feedback, SiFive set out to develop something more ideally suited to this use case. Working with customers like Google, SiFive came up with the Vector Coprocessor Interface eXtension (VCIX), which allows you to plug an accelerator directly into the vector register file of the X280 and communicate on the very fast order of 10 cycles in-and-out. This is helpful for adding complex instructions like color conversions, for example. Overall, VCIX gives you increased performance and much greater data bandwidth, because you go directly into the vector register file, coupled with much lower latency and simplified software.
VCIX connects to the 32, 512-bit registers in the X280 directly and also to the scalar instruction stream, creating a high bandwidth, low latency path directly coupled to the instruction stream of the X280 scalar processor. Designers can not only offload some functions to the software accelerator, but also have the flexibility of having the X280 handle some functions itself. The benefit, as Krste highlighted, is that you can bring your own coprocessor into the RISC-V ecosystem and get a complete software stack and programming environment. You can run full Linux plus a hypervisor with full virtual memory and cache coherent support.
An elegant division of labor with the Google TPU
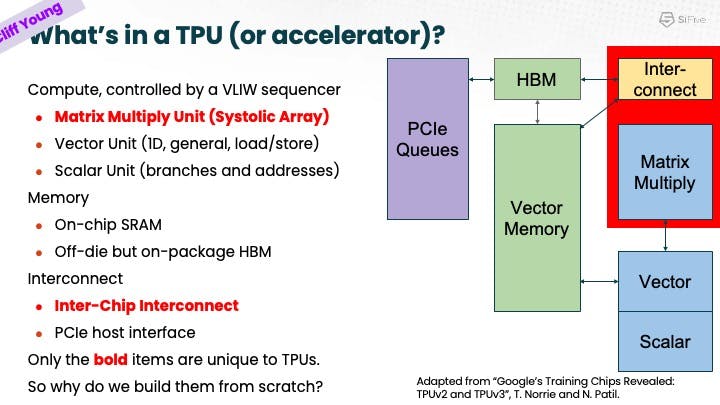
As Cliff explained, Google has significant innovation and investment in their TPU technology, which they essentially built from “scratch” nine years ago. Recognizing the shift toward a more IP-oriented universe, Google wanted to focus on innovation in the most critical areas and where their real strengths and differentiation are, such as in the network and systolic array areas of the TPU.
As Cliff explained, scalar and vector solutions are best left to experts in those technologies, so rather than Google reinventing the wheel, they looked for options and SiFive brought a solution. What if you could reuse a general purpose processor with a general purpose stack? Evaluating a general purpose core vs. accelerator, they looked at how, for example, you could make it easier to program. Looking at VCIX, Google saw an opportunity for flexibility and if you wanted to run Python, for example, right next to the core, you could do so with very low latency.
He further highlighted the promise of VCIX, which is “to get accelerators and general purpose processors right close together.” Rather than hundreds of cycles for on-chip cache or thousands of cycle access through PCIe, you get the benefit of tens of cycles through vector register access.
 Cliff explained what he defined as an important “division of labor,” defining the technical and business operations between a companion core and MXU. A vector unit provides a wide path to memory, and much of the virtual labor is done in VCIX. There is no need to open decoders when you add the Interface overlay with its minimal instructions. And VCIX allows the sending and receiving of instructions with greater flexibility. This flexibility and control allows a clean and efficient division of labor between the Google matrix multiplication unit (MXU) and the X280.
As Cliff concluded, with SiFive VCIX-based general purpose cores “hybridized” with Google MXUs, you can build a machine that lets you “have your cake and eat it too,“ taking full advantage of all the performance of the MXU and the programmability of a general CPU as well as the vector performance of the X280 processor. For Google and other customers, this delivers much more programmable, and flexible future machines.
Cliff explained what he defined as an important “division of labor,” defining the technical and business operations between a companion core and MXU. A vector unit provides a wide path to memory, and much of the virtual labor is done in VCIX. There is no need to open decoders when you add the Interface overlay with its minimal instructions. And VCIX allows the sending and receiving of instructions with greater flexibility. This flexibility and control allows a clean and efficient division of labor between the Google matrix multiplication unit (MXU) and the X280.
As Cliff concluded, with SiFive VCIX-based general purpose cores “hybridized” with Google MXUs, you can build a machine that lets you “have your cake and eat it too,“ taking full advantage of all the performance of the MXU and the programmability of a general CPU as well as the vector performance of the X280 processor. For Google and other customers, this delivers much more programmable, and flexible future machines.
To learn more about how X280 can accelerate your accelerator, contact sales@sifive.com.
Pen Li


Read more Insights from the RISC-V Experts

RISC-V EU Summit 2026: An Ecosystem Coming of Age

Inside the SiFive Performance™ P570 Gen 3: High Performance Efficiency for Next-Generation Consumer and Commercial Applications
